1. Giới thiệu
A Data Pipeline for Fashion Store
Dữ liệu
Workshop này bao gồm những dữ liệu sau:
- Các sản phẩm quần áo được lấy từ Kaggle
- Dữ liệu người dùng, mua hàng, clickstream tự tạo bằng Faker Python
Bối cảnh
Giả sử bạn là Data Engineer tại một cửa hàng bán quần áo online, sếp bạn muốn biết sự quan tâm của khách hàng vào những sản phẩm nào cũng như là phân tích xem xu hướng thời trang hiện tại như thế nào.
Sếp của bạn có những yêu cầu sau:
- Khi người dùng bấm vào hoặc thêm vào giỏ hàng một sản phẩm, trực tiếp được chuyển vào kho lưu trữ, đồng thời chuyển đổi và làm giàu để ML có thể dự đoán xu hướng của thời trang hiện tại và đưa ra các gợi ý sản phẩm cho người dùng real-time. Sau đó dữ liệu gợi ý cho từng User được lưu vào nơi để có thể trực tiếp gợi ý cho người dùng ở trên webiste.
- Yêu cầu thứ 2 là, sau khi người dùng mua hàng, thì kết thúc một ngày, dữ liệu cần được tổng hợp, làm sạch và chuyển vào kho lưu trữ để sẵn sàng cho mục đích phân tích để tìm ra hướng cho chiến lược marketing tiếp theo.
Và ngay sau đó bạn nảy ra ý tưởng triển khai trên Amazon Web Service như sau.
Ý tưởng
Bạn nghĩ ra một hệ thống kết hợp giữa Batch Processing và Real-Time Processing như sau:
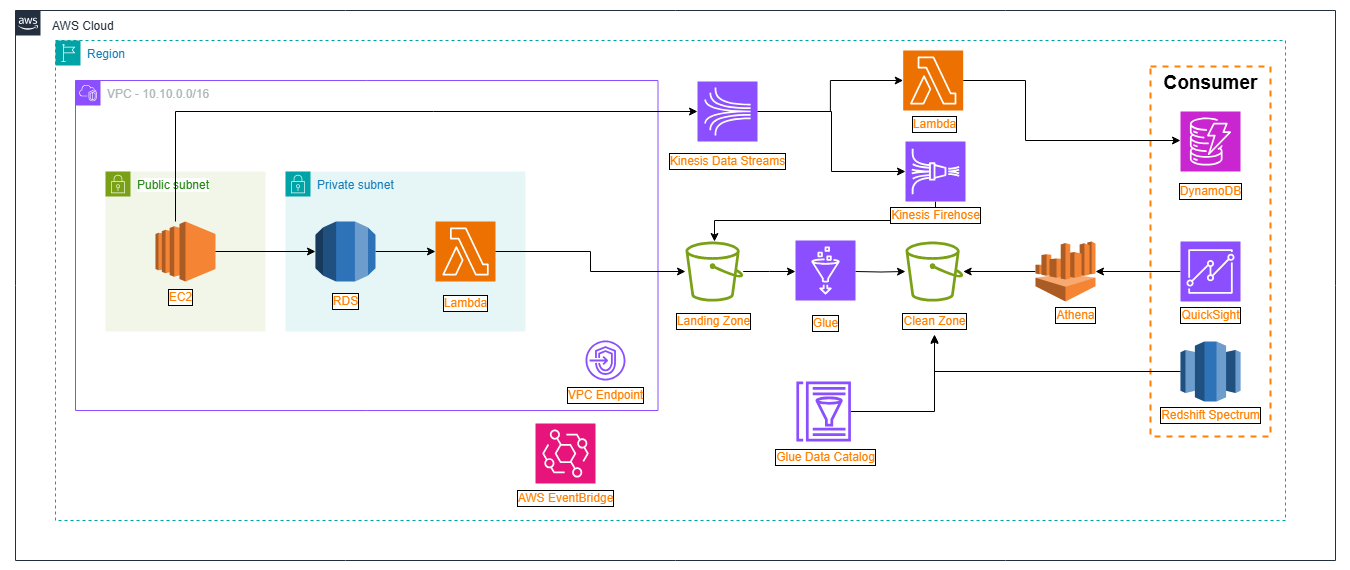
Triển khai hệ thống Database trên Amazon RDS, nơi xử lý các giao dịch mua hàng của người dùng,…
Triển khai hệ thống Data Lake bằng Amazon S3 trên AWS để lưu trữ dữ liệu tổng hợp của cửa hàng.
Xây dựng Glue Data Catalog để có thể trực tiếp phân tích dữ liệu từ Data Lake bằng Athena, hoặc Redshift Spectrum
Đối với luồng dữ liệu tương tác khách hàng (Clickstream), ta sẽ tạo một Kinesis Data Stream sau đó có 2 Consumer:
- Dữ liệu trực tuyến đi qua Lambda, và mỗi khi người dùng tương tác sẽ kích hoạt Lambda Function gợi ý sản phẩm đẩy vào DynamoDB.
- Consumer còn lại đi vào Kinesis Firehose mỗi 5 phút, để đẩy vào Data Lake, nơi Data Analysis phân tích dữ liệu và đưa ra xu hướng thời trang, cũng như là doanh số,…
Lên lịch cho những công việc với Amazon EventBridge lên lịch để tự động hóa quá trình cập nhật dữ liệu
- Sau một ngày dữ liệu từ RDS đi vào S3 vào 00:01 ngày hôm sau.
Sau lúc bạn ghi ra những ý tưởng, đầu bạn nảy ra một hệ thống trên AWS có kiến trúc như sau
Kiến trúc hệ thống
- Lưu ý: Trong phần này, chúng ta sẽ không triển khai dịch vụ QuickSight và Redshift Spectrum, mà chỉ tập trung vào các dịch vụ chính để xây dựng hệ thống gợi ý sản phẩm.